 |
Matrix Data Extractor:
Tabular data extraction from PDF documents is critical task due to diverse PDF templates and Table templates. Some open-source tools do not support all possible types of PDF templates for tabular data extraction. A computer vision based document table detection approach is considered along with Camelot tool to extract tabular information from PDF documents. A post-processing work is necessary after tabular data extraction.
Type of tool: Web application to be deployed on your computer that supports Linux operating system.
Short description of the tool: Extract tabular data and textual data from product technical datasheets (PDF documents)
Matrix Data Extractor (MDE) is a web-based application, which can be deployed on your computer. It identifies document table regions on PDF documents using Computer Vision based Deep Learning, especially Transfer Learning and Object Detection algorithm. It extracts all textual data into text files by applying Optical Character Recognition (OCR) and also extracts tabular data separately in excel files using Camelot python package. It supports to transfer manufacturer names and corresponding technical datasheets names (or PDF filenames) to MongoDB database table for further processing.
Required skills:
- Linux OS (operating system)
- Elementary (Normal) User: No programming
- Advanced User: Python, Basic Deep Learning (PyTorch), Shell scripting
Required programs (step-by-step guide and links provided in GitHub and user guideline blow):
- Python
- Shell script
- Anaconda
- Linux
- Code from GitHub (https://github.com/cslab-hub/MatrixDataExtractor )
)
Disclaimer:
Any support to provide table detection model will not be provided unfortunately after project completion. The accuracy of table detection model depends on various factors such as volume, variety of annotated datasets, hyperparameters of model. You can do your experiment to get better accuracy of your table detection model. To get table detection model weight on Di-Plast dataset, you can request to Semantic Information Systems Research Group, Osnabrueck University, Osnabrueck, Germany ( https://www.informatik.uni-osnabrueck.de/arbeitsgruppen/semantische_informationssysteme.html ).
Screenshots:

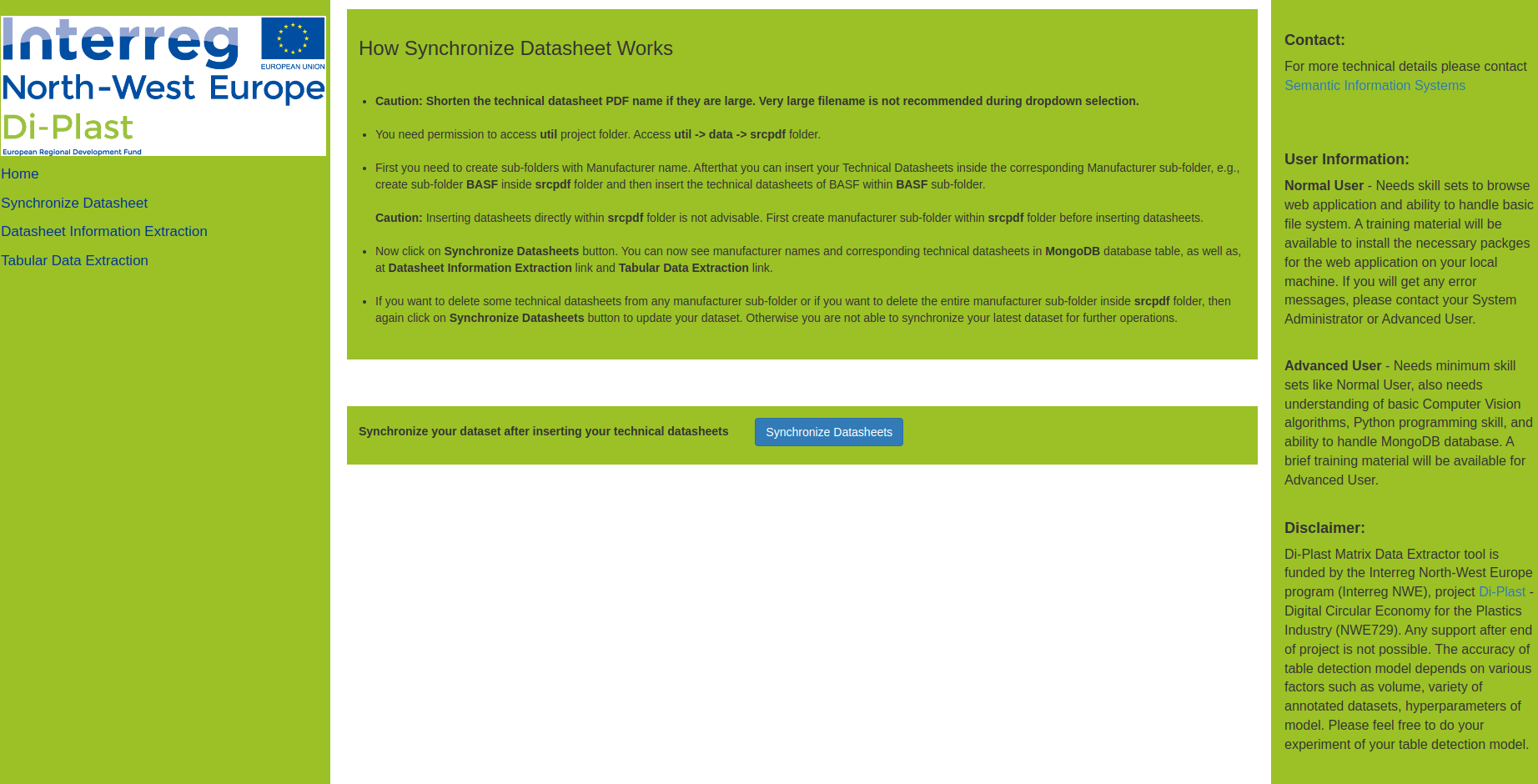
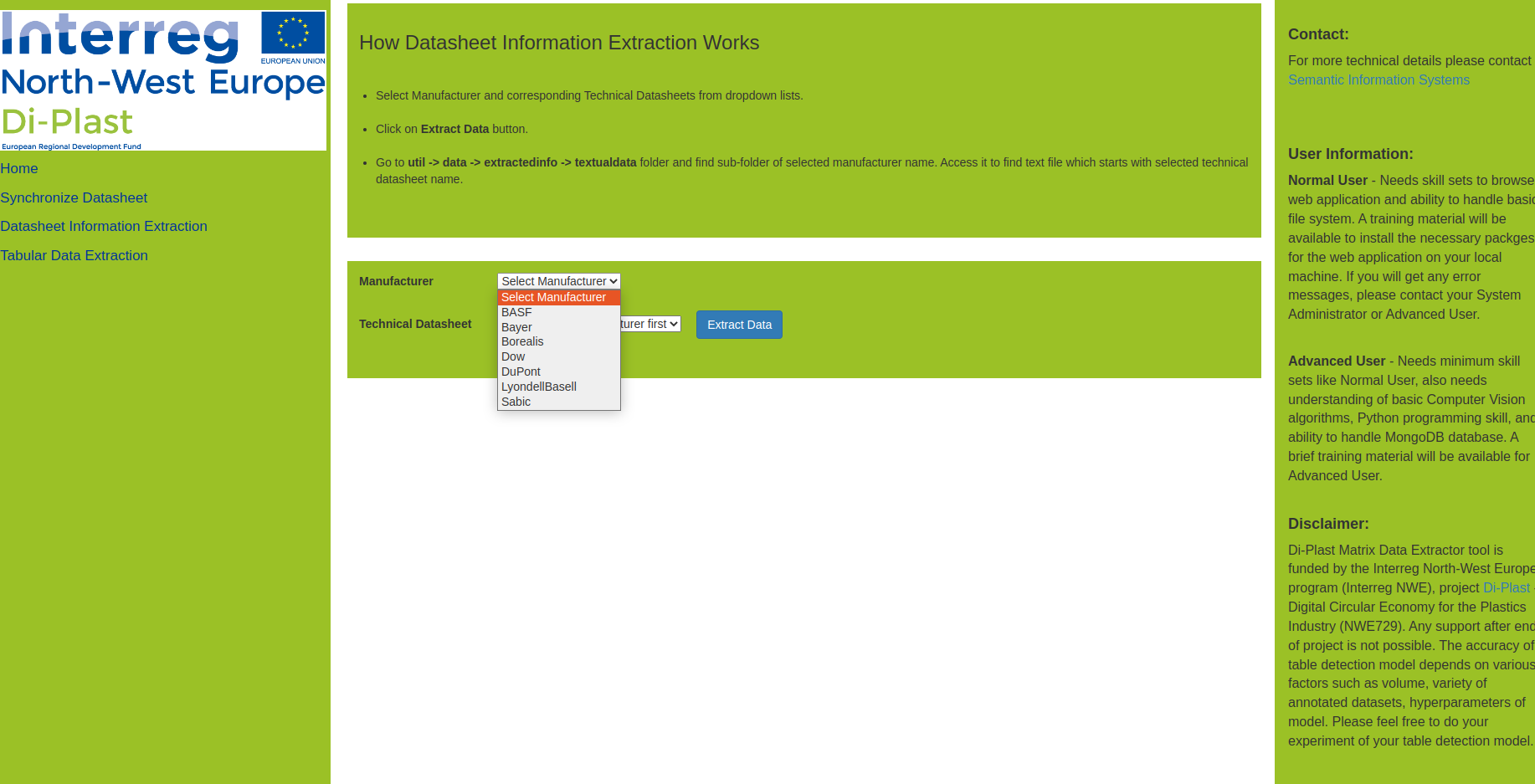
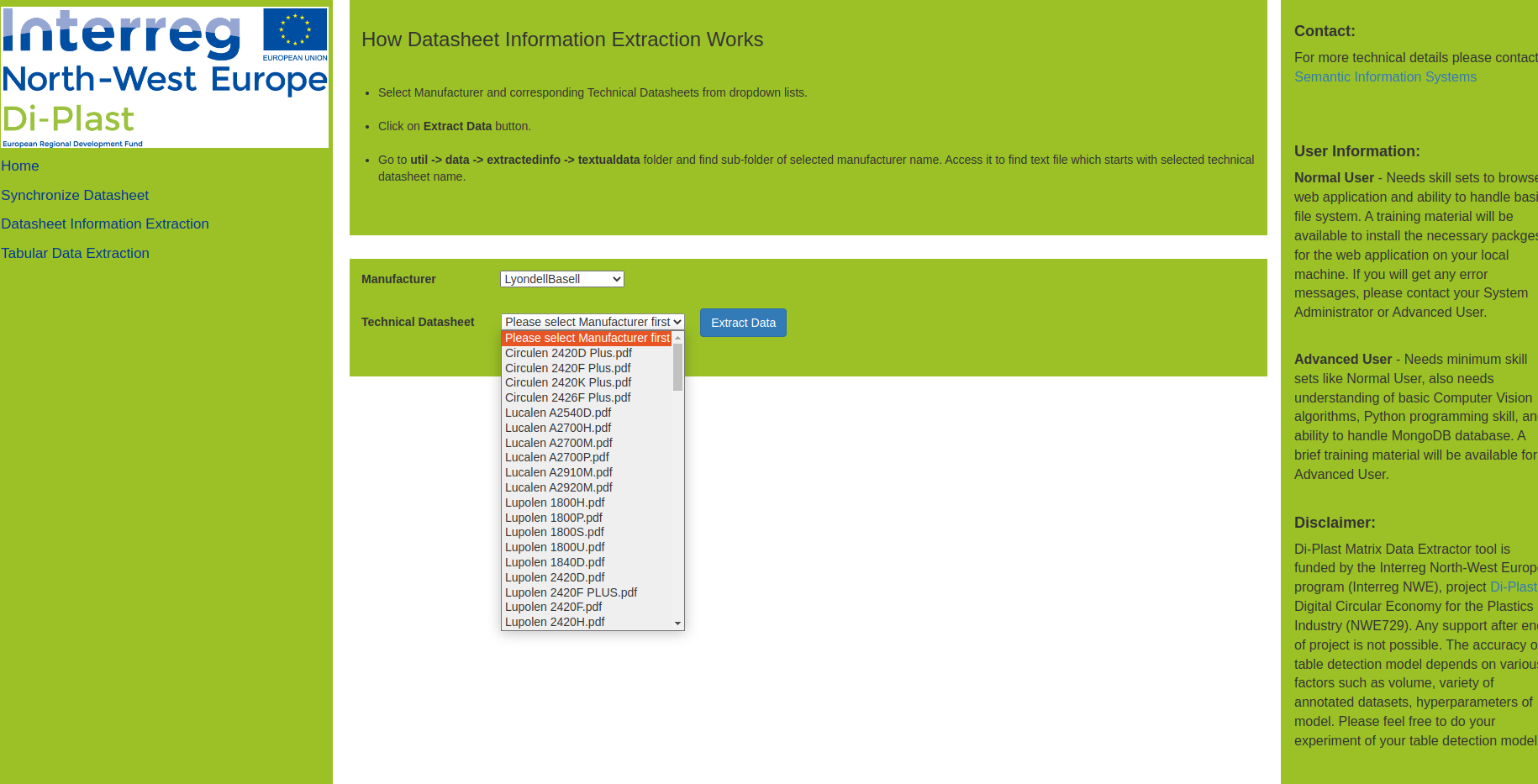
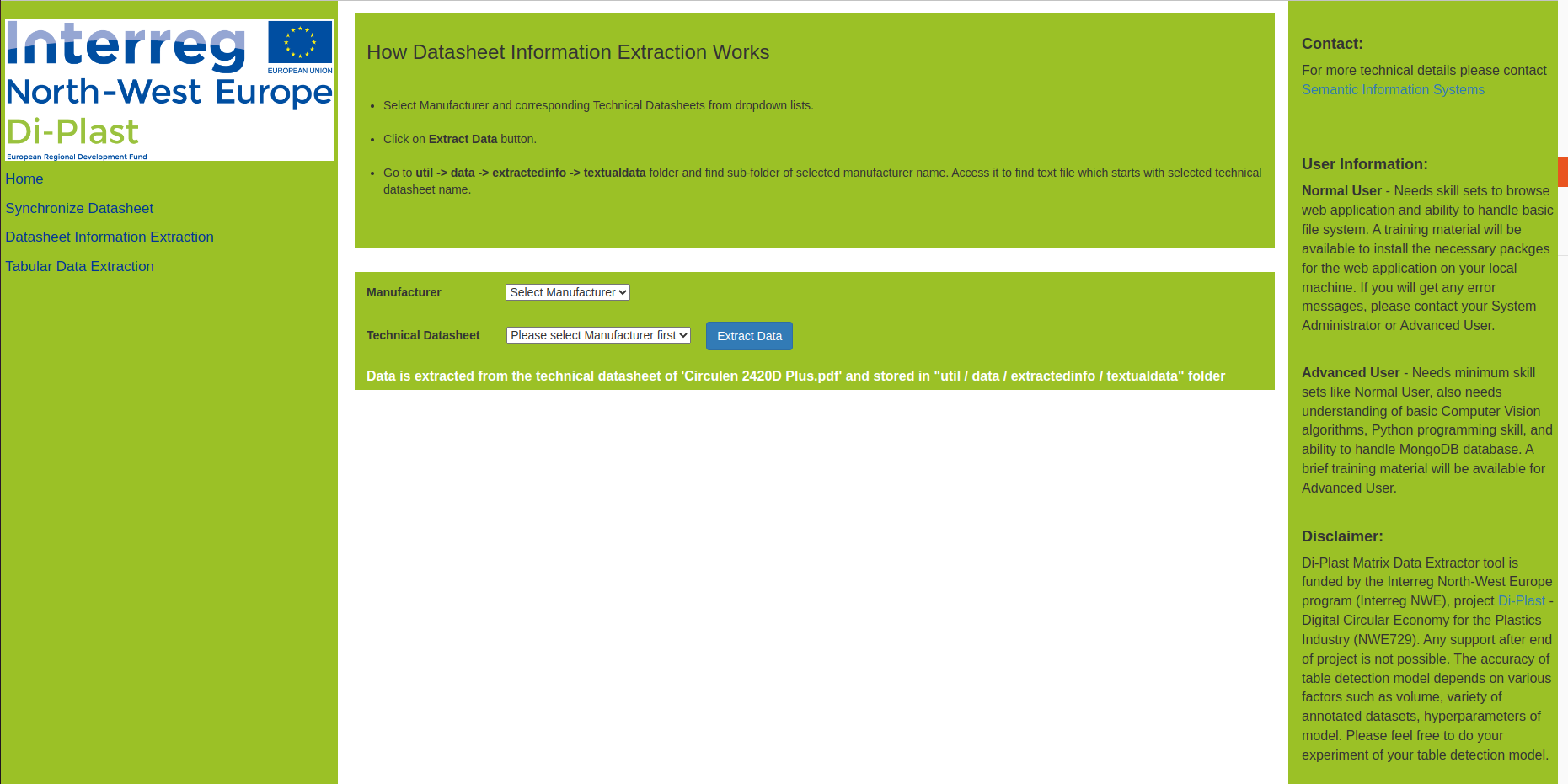
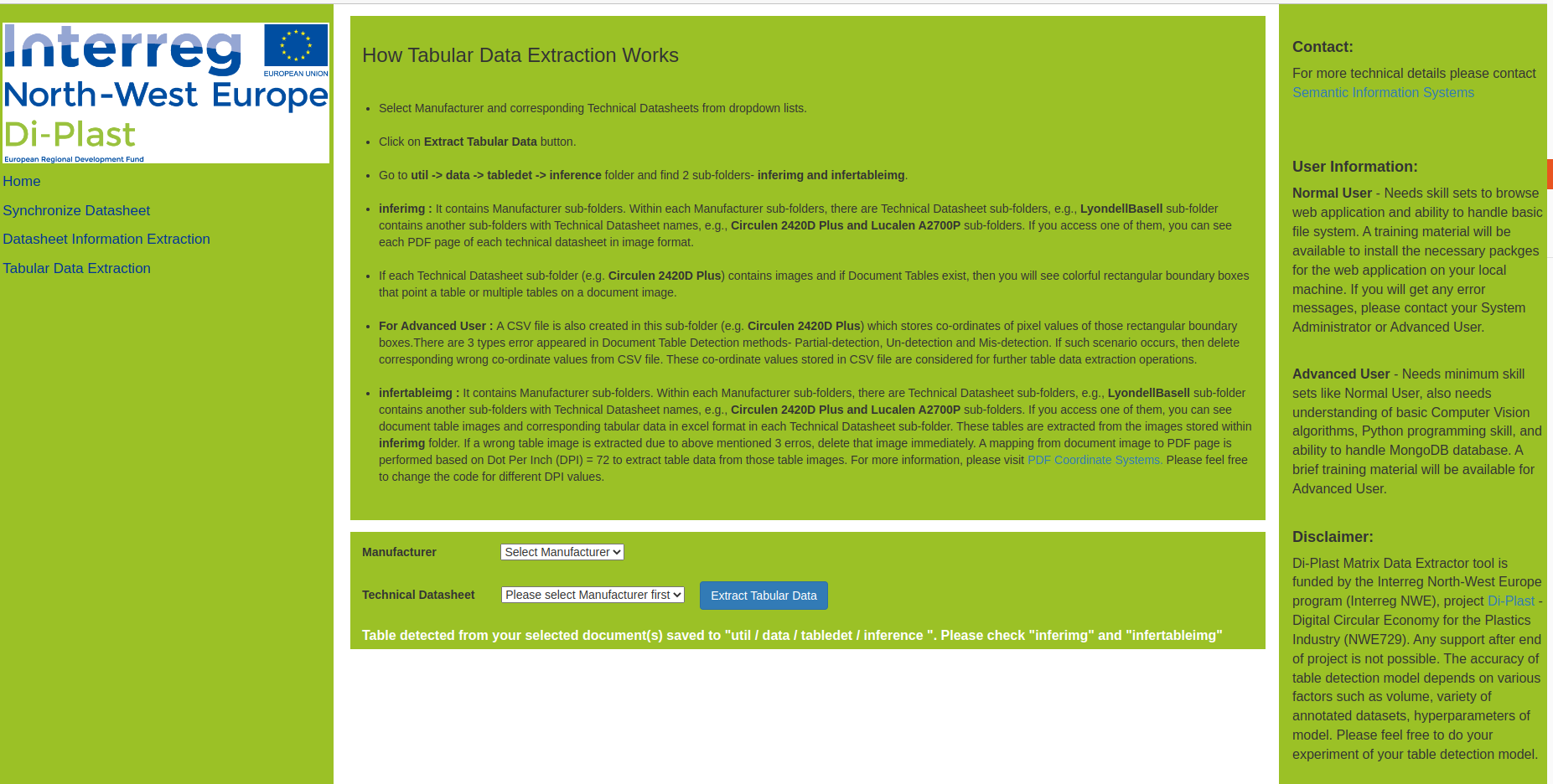
This tool supports you to:
- Extract textual and tabular information from PDF documents.
- ⚠️ For brief overview about the tool, we recommend to open and save the presentation before proceeding: Data Extractor/Di-Plast_MDE_UI.pdf
Example use case:
- Open-source document table detection tools are not suitable enough to extract tabular information from PDF documents by considering all possible document templates and table templates. Due to diverse document templates and table templates, computer vision and transfer learning based document table detection emerged significantly. This tool helps to extract textual and tabular data (in excel files) from your domain specific dataset. The extracted data can be used in Big Data technologies and Natural Language Processing (NLP).
Tool guideline and access:
- ⚠️ We recommend to open and save the user guideline before proceeding: Data Extractor/MatrixDataExtractor_UserGuide.pdf
- Get GitHub https://github.com/cslab-hub/MatrixDataExtractor, copy code into your computer, prepare your annotated dataset, build or request about table detection model weight and model description file, and start using it
Getting Started#
The code for the tool is available at https://github.com/cslab-hub/MatrixDataExtractor
Table Detection : Annotated Datasets, Model Weights, Model Inference#
Table detection model weights and datasets can be provided on request. It is not publicly available. Also a Jupyter Notebook can be provided on request to show model inference result on domain specific dataset.Secret Key for 'backend' Django Web Application:#
Please use Secret Key as 'SECRET_KEY=!zhn#9$0pvr!+jp5q0f-vhvkfp0w$@tpvy4kf20pb89vf#w1q-' in mde.env file without single quotes.
Contact person of the tool:
Arnab Ghosh Chowdhury, mailto:arnab.ghosh.chowdhury@uni-osnabrueck.de form the Osnabrueck University.
Before applying this tool:
We recommend also taking a look at the following Di-Plast tools below. They can help you to gather necessary information and data, help to better prepare your data and continue working with it afterwards:
--> Improve internal information and material flow -> VSM
--> Get guidance to set up a working data infrastructure -> Data Infrastructure Wiki
--> Find the right sensor to survey your process -> Sensor Tool
-->Analyse and Visualize your process data with data analytics -> Data Analytics
-->Get important insights in enhancing your data understanding
-> Exploratory Pattern Analytics
After applying this tool:
-->Match material requirements with material properties -> Matrix